ALCHEMY Benchmarking: Open vs Closed Models
Focused on Retail Domain
ALCHEMY Benchmarking: Open vs Closed Models
Focused on Retail Domain
ALCHEMY Benchmarking: Open vs Closed Models
Focused on Retail Domain
This study focuses on evaluating various language models' performance on retail-related queries using the Alchemy framework.
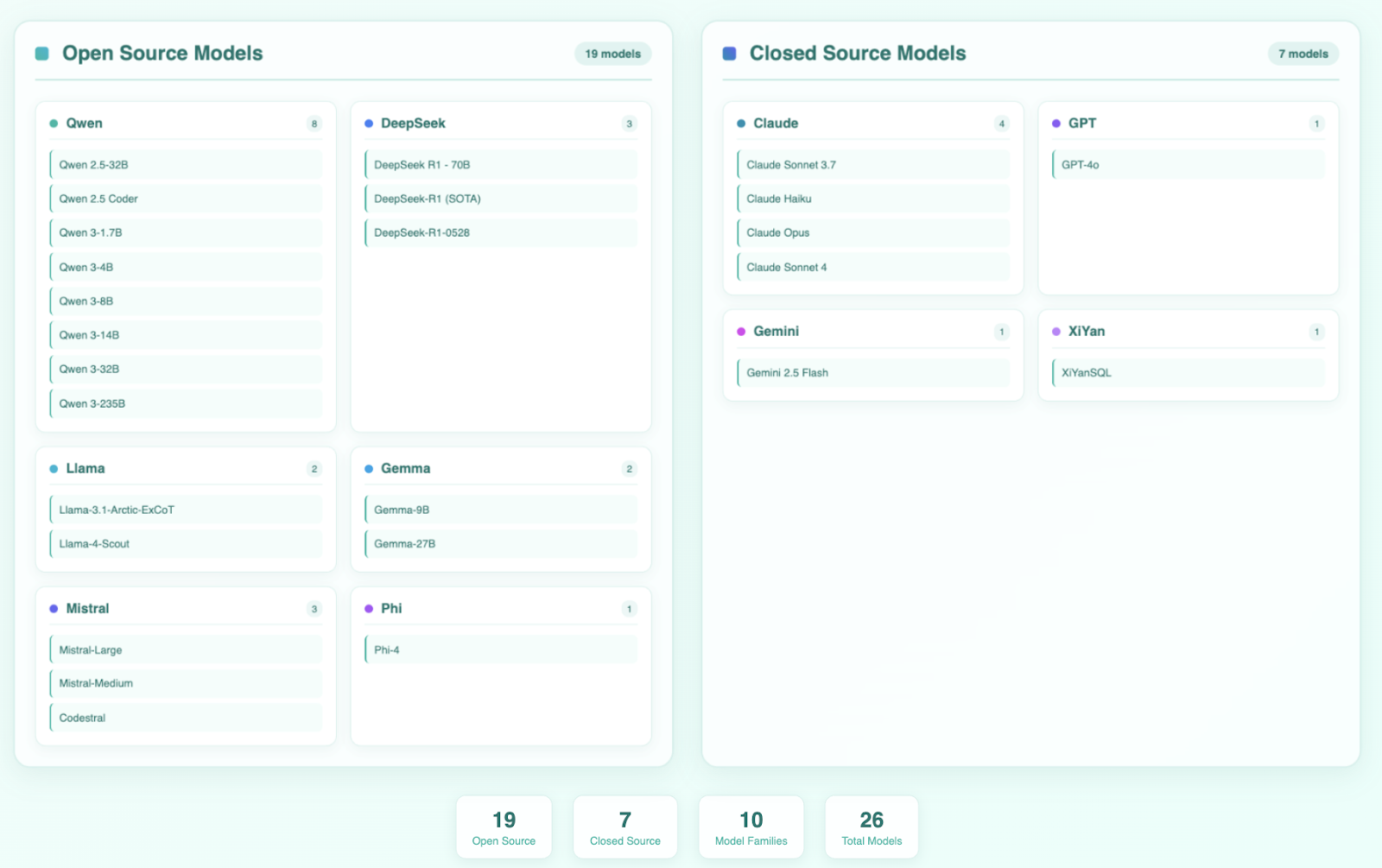
Models included in the benchmarking study -
Most model benchmarks today are centered around structured academic or technical tasks—such as logical reasoning (GPQA), high school math (AIME), coding benchmarks (SWE Bench), or tool use (BFCLU). These tasks provide a sense of raw model capability, but they rarely reflect the messy, cross-domain, context-rich questions that real-world stakeholders and business users actually ask.
There is a major gap in evaluating models for enterprise use cases. Almost no benchmarks today test how well models perform in domain-specific, operational contexts—especially in verticals like retail, logistics, or financial services.
Enterprises require AI systems that can understand domain-specific language, reason over structured and unstructured data, and answer real - world business questions—like evaluating store performance or estimating demand in new locations. These tasks demand multi-step reasoning, geographic context, and behavioral insights, which current benchmarks fail to test—limiting their value for enterprise AI deployment.
Observations
Methodology
The evaluation process is built on top of Alchemy's architecture, which enables:
Translation of user queries into structured representations
Semantic grounding through business concepts
Execution over complex retail schemas
Synthetic Retail Dataset Curation
We constructed a synthetic retail dataset using our experience with enterprise retailers, modeled on data from nearly 200 retail store locations. The schema mirrors actual retail systems, with standard dimensions (product, store, customer, time, location) and fact tables (sales, inventory, transactions, foot traffic).
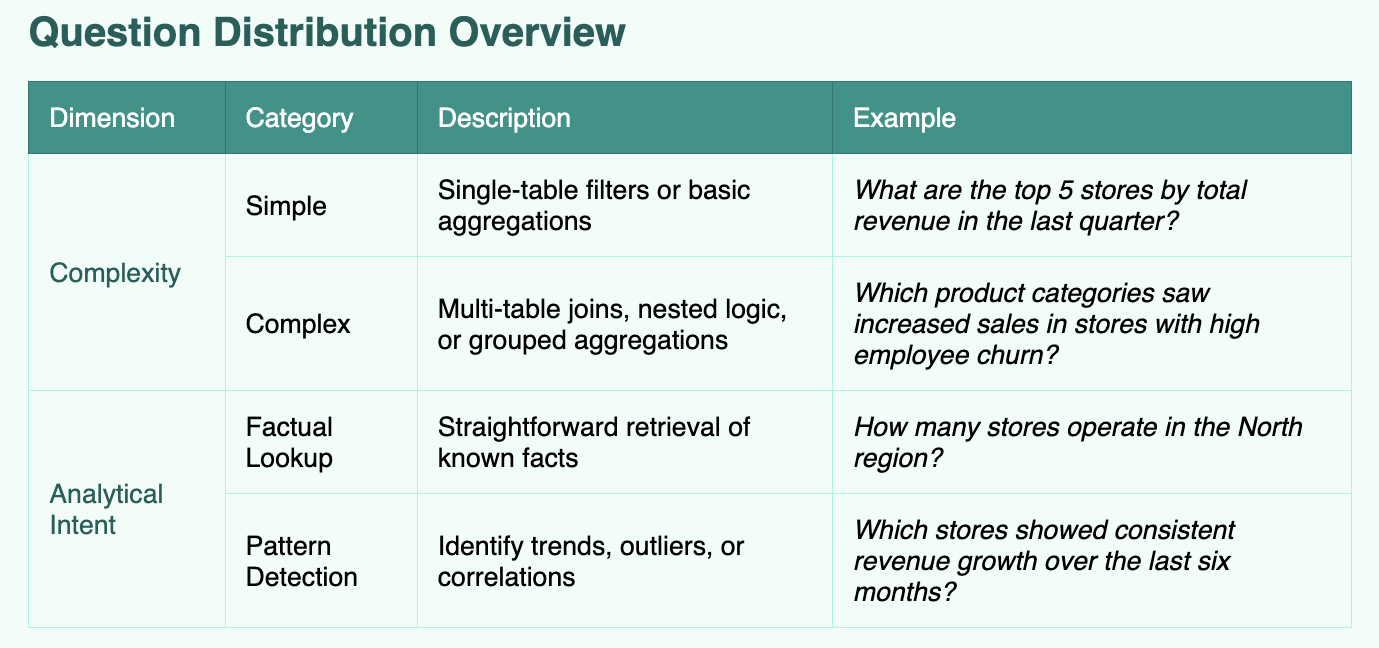
Question Creation
To simulate realistic enterprise workflows, we constructed natural language questions grounded in retail business logic. These questions were designed to test LLMs across three dimensions: conceptual understanding, query reasoning, and data structure awareness.
Importantly, the question corpus is not hypothetical—it is derived from actual queries we've seen asked to Alchemy by retail industry users.
Propheus' Semantic Data Kernel
After curating the dataset, we map it into business concepts—abstract representations that capture meaningful understanding from underlying data structures.
For example, from basic tables like:
SALES_TRANSACTIONS (transaction_id, store_id, date, amount)
STORE (store_id, location, size, type)
We derive concepts like Store Performance—not simply by joining tables, but by constructing higher-order representations that combine key attributes, behavioral indicators, and contextual business logic. These abstractions reflect how decision-makers think about performance in practice, beyond what raw data alone can capture.
A good AI system should know what “store performance” means in context—not just pull numbers from a database. It should factor in location, foot traffic, store size, and customer behavior—just like your teams would.
These concepts act as semantic anchors, allowing Alchemy to interpret questions in business terms rather than just SQL logic.
Answer Validation & Benchmarking with SOTA Models
To evaluate how effectively different language models handle real-world retail queries, we designed a two-tiered validation process:
Agents Pathways – ensuring the model produces a valid, executable query aligned with the business concept.
Answer Accuracy Validation – verifying that the model's answer matches the expected result based on the ground truth data.
We tested a set of state-of-the-art (SOTA) language models—across a benchmark suite of queries derived from our synthetic retail dataset.
Metrics Tracked
Answer Accuracy: Did the final response match the correct result from executing the SQL?
Query Comprehension: Did the model understand the higher-level retail concept being asked (e.g., store performance, sales comparison)?
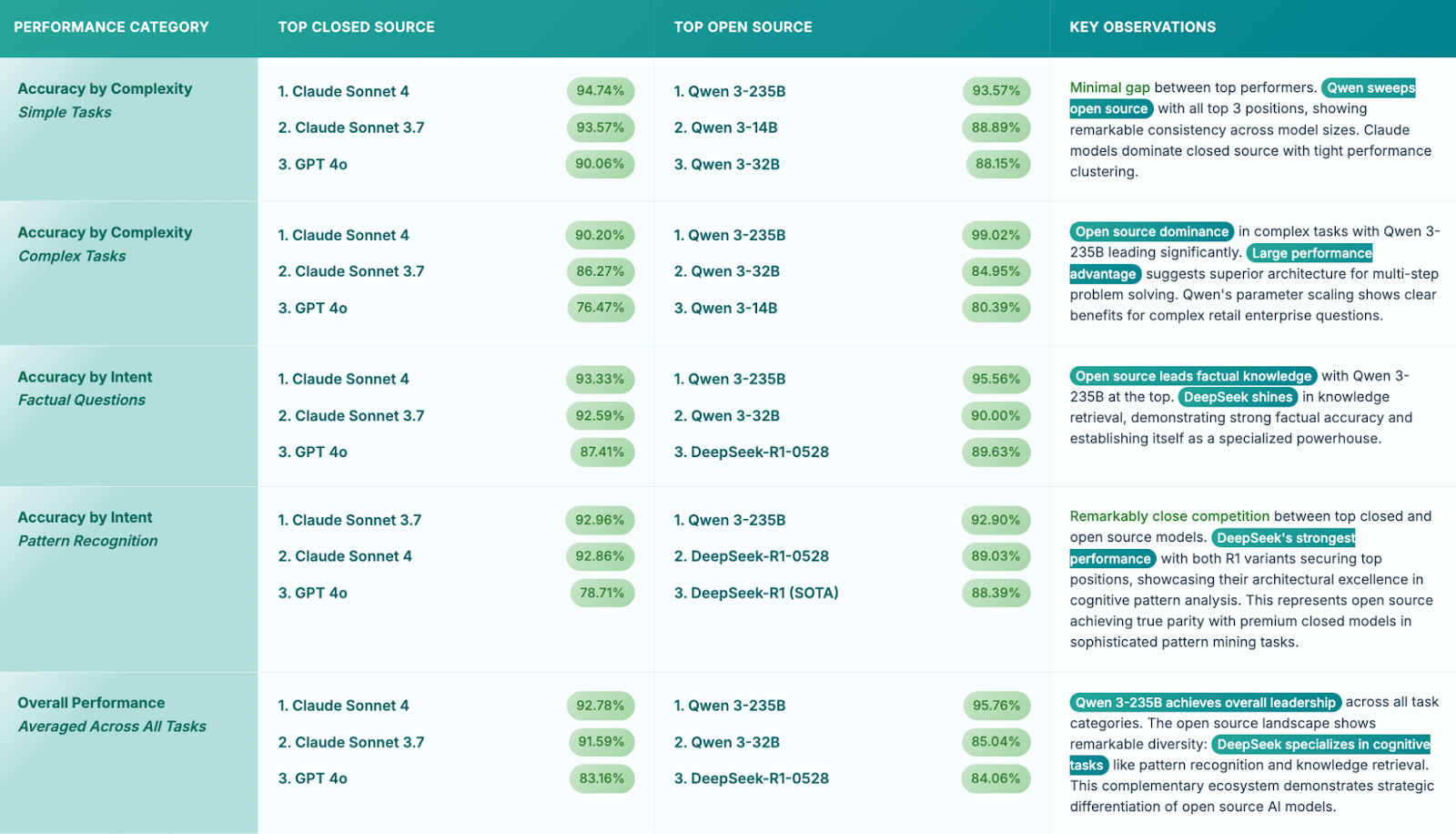
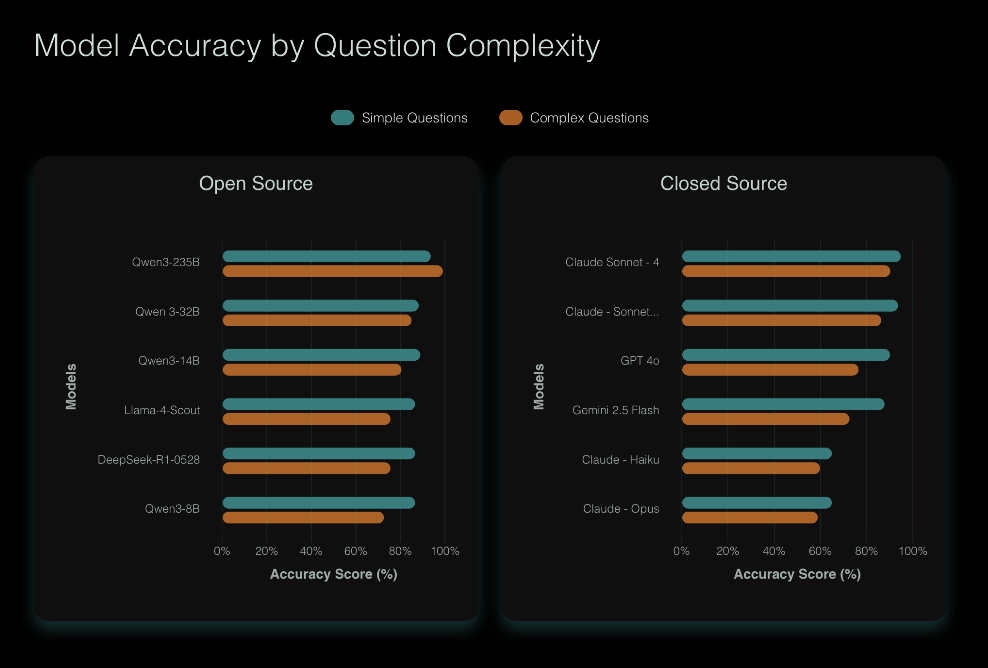
Results
Our Conclusions

Sign Up for Alchemy Playground!
This study focuses on evaluating various language models' performance on retail-related queries using the Alchemy framework.
Models included in the benchmarking study -
Most model benchmarks today are centered around structured academic or technical tasks—such as logical reasoning (GPQA), high school math (AIME), coding benchmarks (SWE Bench), or tool use (BFCLU). These tasks provide a sense of raw model capability, but they rarely reflect the messy, cross-domain, context-rich questions that real-world stakeholders and business users actually ask.
There is a major gap in evaluating models for enterprise use cases. Almost no benchmarks today test how well models perform in domain-specific, operational contexts—especially in verticals like retail, logistics, or financial services.
Enterprises require AI systems that can understand domain-specific language, reason over structured and unstructured data, and answer real - world business questions—like evaluating store performance or estimating demand in new locations. These tasks demand multi-step reasoning, geographic context, and behavioral insights, which current benchmarks fail to test—limiting their value for enterprise AI deployment.
Observations
Methodology
The evaluation process is built on top of Alchemy's architecture, which enables:
Translation of user queries into structured representations
Semantic grounding through business concepts
Execution over complex retail schemas
Synthetic Retail Dataset Curation
We constructed a synthetic retail dataset using our experience with enterprise retailers, modeled on data from nearly 200 retail store locations. The schema mirrors actual retail systems, with standard dimensions (product, store, customer, time, location) and fact tables (sales, inventory, transactions, foot traffic).
Question Creation
To simulate realistic enterprise workflows, we constructed natural language questions grounded in retail business logic. These questions were designed to test LLMs across three dimensions: conceptual understanding, query reasoning, and data structure awareness.
Importantly, the question corpus is not hypothetical—it is derived from actual queries we've seen asked to Alchemy by retail industry users.
Propheus' Semantic Data Kernel
After curating the dataset, we map it into business concepts—abstract representations that capture meaningful understanding from underlying data structures.
For example, from basic tables like:
SALES_TRANSACTIONS (transaction_id, store_id, date, amount)
STORE (store_id, location, size, type)
We derive concepts like Store Performance—not simply by joining tables, but by constructing higher-order representations that combine key attributes, behavioral indicators, and contextual business logic. These abstractions reflect how decision-makers think about performance in practice, beyond what raw data alone can capture.
A good AI system should know what “store performance” means in context—not just pull numbers from a database. It should factor in location, foot traffic, store size, and customer behavior—just like your teams would.
These concepts act as semantic anchors, allowing Alchemy to interpret questions in business terms rather than just SQL logic.
Answer Validation & Benchmarking with SOTA Models
To evaluate how effectively different language models handle real-world retail queries, we designed a two-tiered validation process:
Agents Pathways – ensuring the model produces a valid, executable query aligned with the business concept.
Answer Accuracy Validation – verifying that the model's answer matches the expected result based on the ground truth data.
We tested a set of state-of-the-art (SOTA) language models—across a benchmark suite of queries derived from our synthetic retail dataset.
Metrics Tracked
Answer Accuracy: Did the final response match the correct result from executing the SQL?
Query Comprehension: Did the model understand the higher-level retail concept being asked (e.g., store performance, sales comparison)?
Results
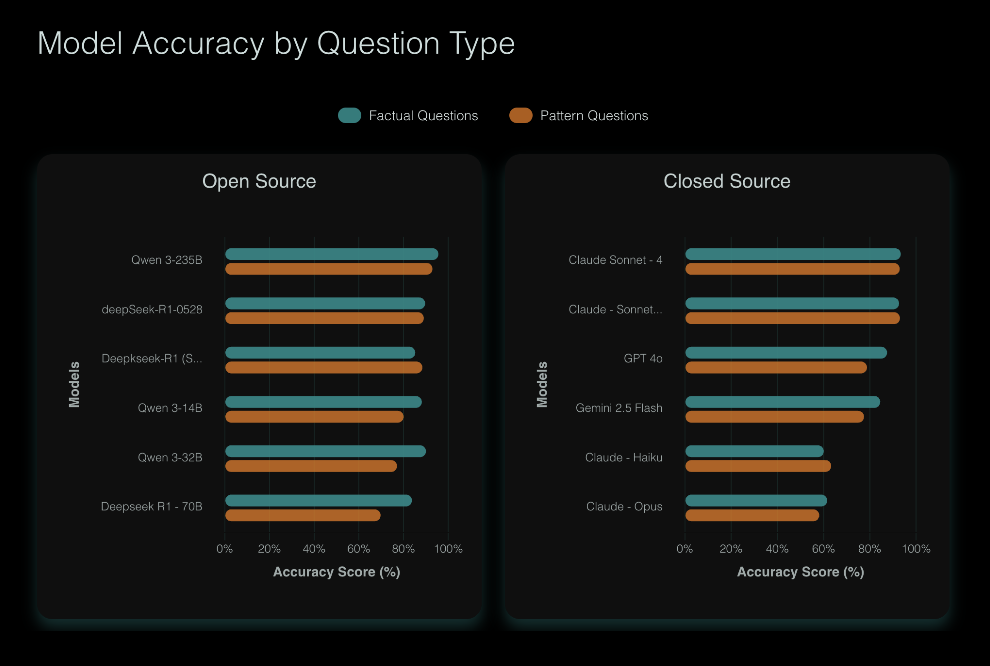
Our Conclusions
Sign Up for Alchemy Playground!
This study focuses on evaluating various language models' performance on retail-related queries using the Alchemy framework.
Models included in the benchmarking study -
Most model benchmarks today are centered around structured academic or technical tasks—such as logical reasoning (GPQA), high school math (AIME), coding benchmarks (SWE Bench), or tool use (BFCLU). These tasks provide a sense of raw model capability, but they rarely reflect the messy, cross-domain, context-rich questions that real-world stakeholders and business users actually ask.
There is a major gap in evaluating models for enterprise use cases. Almost no benchmarks today test how well models perform in domain-specific, operational contexts—especially in verticals like retail, logistics, or financial services.
Enterprises require AI systems that can understand domain-specific language, reason over structured and unstructured data, and answer real - world business questions—like evaluating store performance or estimating demand in new locations. These tasks demand multi-step reasoning, geographic context, and behavioral insights, which current benchmarks fail to test—limiting their value for enterprise AI deployment.
Observations
Methodology
The evaluation process is built on top of Alchemy's architecture, which enables:
Translation of user queries into structured representations
Semantic grounding through business concepts
Execution over complex retail schemas
Synthetic Retail Dataset Curation
We constructed a synthetic retail dataset using our experience with enterprise retailers, modeled on data from nearly 200 retail store locations. The schema mirrors actual retail systems, with standard dimensions (product, store, customer, time, location) and fact tables (sales, inventory, transactions, foot traffic).
Question Creation
To simulate realistic enterprise workflows, we constructed natural language questions grounded in retail business logic. These questions were designed to test LLMs across three dimensions: conceptual understanding, query reasoning, and data structure awareness.
Importantly, the question corpus is not hypothetical—it is derived from actual queries we've seen asked to Alchemy by retail industry users.
Propheus' Semantic Data Kernel
After curating the dataset, we map it into business concepts—abstract representations that capture meaningful understanding from underlying data structures.
For example, from basic tables like:
SALES_TRANSACTIONS (transaction_id, store_id, date, amount)
STORE (store_id, location, size, type)
We derive concepts like Store Performance—not simply by joining tables, but by constructing higher-order representations that combine key attributes, behavioral indicators, and contextual business logic. These abstractions reflect how decision-makers think about performance in practice, beyond what raw data alone can capture.
A good AI system should know what “store performance” means in context—not just pull numbers from a database. It should factor in location, foot traffic, store size, and customer behavior—just like your teams would.
These concepts act as semantic anchors, allowing Alchemy to interpret questions in business terms rather than just SQL logic.
Answer Validation & Benchmarking with SOTA Models
To evaluate how effectively different language models handle real-world retail queries, we designed a two-tiered validation process:
Agents Pathways – ensuring the model produces a valid, executable query aligned with the business concept.
Answer Accuracy Validation – verifying that the model's answer matches the expected result based on the ground truth data.
We tested a set of state-of-the-art (SOTA) language models—across a benchmark suite of queries derived from our synthetic retail dataset.
Metrics Tracked
Answer Accuracy: Did the final response match the correct result from executing the SQL?
Query Comprehension: Did the model understand the higher-level retail concept being asked (e.g., store performance, sales comparison)?
Results
Our Conclusions
Sign Up for Alchemy Playground!
©Propheus Pte. Ltd. 2025
©Propheus Pte. Ltd. 2025
